Keywords
artificial intelligence - clinical decision support - clinical informatics - clinical information systems
Background and Significance
Background and Significance
Large language models (LLMs), which are a type of artificial intelligence (AI), are designed to process and understand human language. They are usually trained on massive amounts of text. For example, ChatGPT is a very efficient LLM that has garnered a great deal of public attention for its capabilities since its recent introduction in late 2022.[1]
[2]
[3] The possible health care applications of LLMs are numerous. Representative examples include generating clinical documentation, personalized educational materials, and original scientific manuscripts.[4]
[5]
One well-known limitation of ChatGPT is its tendency for “hallucination,” the generation of text that is perceived as convincing but is not accurate.[6] A second limitation is that ChatGPT can propagate bias that is intrinsic in the training data. These issues have raised concerns about the safety of LLM use in health care. Specifically, some researchers envision scenarios where ChatGPT could provide clinical care advice that is outdated, inaccurate, or incomplete.[7]
[8]
[9]
[10]
Determining the best uses of LLMs in health care has been the focus of recent studies. In a prior publication, clinicians with informatics expertise evaluated LLMs for clinical decision support and concluded that they may provide valuable assistance (Liu et al, 2023).[11] However, that study did not address the experience of novice LLM users. Furthermore, few studies have investigated health care provider comfort with LLMs or used both quantitative and qualitative methods. Those studies either asked general questions about the suitability of LLMs in different health care domains[12]
[13] or compared it to human performance on one health care delivery service.[14]
Presently, applications of LLMs are being developed at a rapid pace and could have widespread adoption within health care by novice and expert users alike. The most ethical and effective implementation of the technology must consider user requirements and concerns from representative stakeholders of this technology in the clinical setting. In this study, we surveyed diverse practicing clinicians about using LLMs for tasks in clinical practice, research, and education and summarized their perceptions of the potential and limitations of LLMs, to inform the development of clinically meaningful evaluation standards for LLMs to ensure their appropriate and ethical implementation in clinical settings.
Methods
Study Design and Sampling
The survey instrument, which is shown in [Supplementary Appendix 1] (available in the online version only), was developed by two authors with both clinical and informatics experience (M.S., B.I.) and refined based on feedback from a third author (E.R.G.). It was implemented through Qualtrics (Qualtrics, Provo, UT), took approximately 15 minutes to complete, and gauged clinicians' perceptions on the appropriateness of using LLMs in clinical practice, research, and education.
The opening questions quantified participants' experience in clinical medicine and informatics with multiple choice answers. Next, there were questions that asked if the amount of LLM experience in health care within the past year had exceeded 50 hours. Then, there were questions that prompted rating the appropriateness of LLM use for 23 different tasks in clinical practice, research, and education on a 5-point Likert scale (i.e., Highly Appropriate to Highly Inappropriate). Those tasks represented a sample of proposed LLM uses that were synthesized from the literature and included, but were not limited to, optimizing alerts for clinical decision support, providing a differential diagnosis, writing a discharge summary, recommending treatment options, translating radiology reports into layperson language, writing scientific manuscripts, and generating personalized study plans for students or trainees among others.[2]
[6]
[7]
[8]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
[24]
[25]
We distributed the proposed clinical practice tasks over two questions, and had one question for research tasks and one question for education tasks. The purpose of this section was to measure the appropriateness of these tasks by category and to determine if any individual tasks were negative or positive outliers. We hypothesized that perceptions about the strengths, limitations, and ethical concerns about LLMs could contribute to the ratings. Therefore, we had open-ended questions about each of those as well as an open-ended question about other possible uses of LLMs.
Data Collection
We recruited participants with an email invitation that was sent to a listserv of clinicians at Columbia University Irving Medical Center and by word of mouth. To be eligible, participants needed to be practicing clinicians affiliated with Columbia University within the past 12 months and were able to comprehend and communicate fluently in English. Respondents were compensated with a $20 Amazon Gift Card for completing the survey.
Data Analysis
We calculated descriptive statistics on the participants and tabulated their ratings for each question. Two independent reviewers performed an inductive thematic analysis with the narrative comments. Both of them performed independent coding of free text using NVivo (Version 14) with generation of themes. They met regularly for a total of three times and developed themes iteratively. Once a consensus was reached, the reviewers determined a final list of themes and applied them to the narrative comments. A third reviewer was available to resolve any discrepancies.
Results
We recruited practicing clinicians from internal medicine, otolaryngology, ophthalmology, pediatrics, urology, anesthesiology, neurosurgery, and general surgery. We distributed a prescreening survey to 350 clinicians, among whom 108 responded, and 30 were eligible and enrolled. All completed the survey. Their demographics are shown in [Table 1].
Table 1
Participant information
|
Survey characteristics
|
N (%)
|
|
Clinical Training
|
|
1–2 years
|
12 (40)
|
|
3–5 years
|
3 (10)
|
|
> 5 years
|
15 (50)
|
|
Informatics Training
|
|
None
|
26 (86.7)
|
|
1–2 years
|
3 (10)
|
|
3+ years
|
1 (3.3)
|
|
LLM use within the past 12 months
|
|
< 50 hours
|
28 (93.3)
|
|
50+ hours
|
2 (6.7)
|
Abbreviations: LLM, large language model; N, number; %, percent.
Survey Ratings
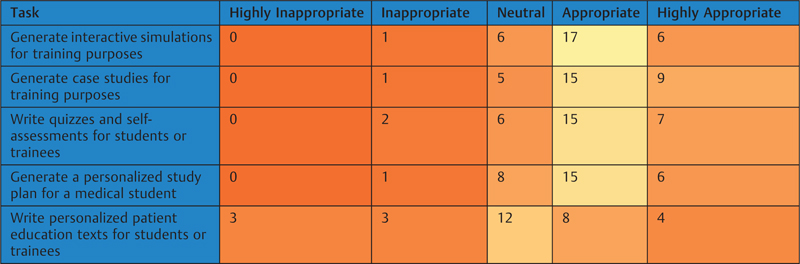
Heat maps of the ratings for clinical, research, and education tasks are shown in [Tables 2]
[3]
[4]. Of the 23 tasks, 16 (69.6%) had positive ratings by at least half of the participants. The highest rated tasks were “assist with vaccine development by predicting the antigenicity of different proteins from genomic data” (25 positive ratings from 30 participants), “model the spread and transmission of an infectious disease” (25 positive ratings), “generate case studies for training purposes” (24 positive ratings), “monitor data for an emerging disease cluster” (24 positive ratings), and “generate alerts to improve compliance with clinical guidelines” (24 positive ratings). In contrast, 7 out of 23 tasks had positive ratings by fewer than half of the participants. Two of the tasks with the lowest number of positive ratings also had the highest number of negative ratings, which were “Respond to patient questions about a radiology report” (7 positive ratings, 16 negative ratings), and “Write an original scientific manuscript” (5 positive ratings, 20 negative ratings).
Table 2
Heatmap of ratings for large language model uses in clinical practice tasks (orange = lowest; yellow = highest)
|

|
Table 3
Heatmap of ratings for large language model uses in research tasks (orange = lowest; yellow = highest)
|

|
Table 4
Heatmap of ratings for large language model uses in education tasks (orange = lowest; yellow = highest)
|
|
Thematic Analysis
We received 20 open-ended responses about LLM strengths, limitations, and ethical concerns, respectively. The responses about the limitations and ethical concerns of LLMs were very similar; therefore, we combined them for a total of 40 responses. There were 19 responses about additional uses of LLMs. The themes and corresponding examples are shown in [Table 5]. Some respondent answers addressed multiple themes and were mapped to each of them. The full responses to our open-ended questions are shown in [Supplementary Appendix 2] (available in the online version only).
Table 5
Summary of narrative comments about perceived advantages, ethical concerns, and clinical applications of large language models with representative examples
|
Advantages (n = 20)
|
Ethical concerns (n = 40)
|
Recommended clinical applications for using LLMs (n = 19)
|
|
Aptitude for specific tasks (n = 10)
Ability to generate first drafts with low effort
It can also help students and providers come up with a differential diagnosis
Theoretically could reduce paperwork/administrative work
Ability to write code for novice programmers
|
False information (n = 15)
Hallucination, fabrication, reinforcement of assumptions and biases
With the confabulation/hallucination issue, does not allow for the uncertainty that is almost always present in medicine
Its propensity to make up information
|
Drafting documentation (n = 8)
Note templates/drafts, especially for routine and predictable things like procedures
|
|
Synthesis ability (n = 9)
Synthesize large amounts of data quickly
Good at synthesizing information in a clear concise fashion
|
Worsens patient care (n = 14)
This technology if unchecked at a patient care level may have serious implications of harm to patients
Major concern about inappropriate use by lay public to self-diagnose
Also worry about who gets care from health care workers versus from direct-to-patient LLM which could be less personalized, and initially less validated and trustworthy
|
Decision support (n = 5)
Anything providing recommendations to patients or providers
Flagging concerning trends (VS, laboratory values) earlier; providing guidance in managing chronic conditions
|
|
Efficiency (n = 8)
Saves time and improves efficiency
|
Data bias (n = 12)
Results are only as good as the datasets that are fed into the LLM
Given the fast pace of evidence in health care, can be trained on old evidence
Poor data quality leads to poor answers
Replicates existing biases
|
Patient communication (n = 4)
Drafting replies to patient messages in the outpatient inbox that are modeled off of the provider's communication style
|
|
Accuracy (n = 5)
Fairly accurate and provide higher quality, more personalized information than most patient-facing information available on the internet
|
Human oversight critical (n = 7)
They should not replace informed decision-making for patients or clinical decision-making for doctors completely
|
–
|
|
Accessibility (n = 4)
Translating medical documents into plain English
|
Impersonal (n = 6)
Worry about who gets care from health care workers versus from direct-to-patient LLM which could be less personalized
|
–
|
|
–
|
Legal concerns (n = 5)
Gray area of ethical/legal limitations
|
–
|
|
–
|
Privacy (n = 3)
Worries of patient confidentiality
|
–
|
|
–
|
Worsens clinicians (n = 2)
If we become reliant on LLMs, we may lose opportunities to practice interpreting/synthesizing data ourselves
|
–
|
Abbreviation: LLM, large language model; VS, vital signs.
Discussion
LLMs promise to transform health care. A human-centered approach is critical to ensure ethical and effective implementation of this powerful technology in clinical settings. This was the first study of clinical practitioners, who were mostly novice LLM users and from diverse health care domains, to rate tasks that may be improved by LLMs.
The fundamental theorem of biomedical informatics is user augmentation so that “a person working in partnership with an information resource is better than that same person unassisted.”[26] Similarly, the clinicians who we studied were encouraging of having LLMs as their assistants. The tasks that leveraged LLMs for supportive roles were rated the highest. In the qualitative analysis, emerging themes were that LLMs were highly skilled at different tasks; however, there were ethical concerns about using the technology. Supportive LLM roles may have been more popular, because in those scenarios clinicians could correct for false information that the algorithms might generate.
Therefore, we expect that clinicians would prefer to have LLMs function more like trainees or physician extenders than attending physicians. LLMs could assist clinicians by drafting notes and reports, making suggestions for patient triage, extracting patient information from charts, and identifying discrepancies from standard patient care. Since LLMs are very skilled at processing large amount of data, they could help monitor patients in critical care and perioperative settings. Also, they could help translate medical information between languages, or from technical jargon into layperson language. The contributions of LLMs to these tasks could be reviewed by a clinician.
However, the notion of allowing LLMs to function without supervision in clinical practice raises ethical concerns. They have a propensity to produce false information and propagate data bias, which could lead to incorrect medical decisions. Furthermore, LLMs lack human empathy, which could be a source of mistrust with patients. Instead, patients are more likely to trust medical advice from a clinician because of the human connection. Overall, we believe that clinicians would prefer to have LLMs assist them instead of replace their practice.
Our study participants were encouraging of LLM assistance in the research and education domains as well. In research, the processing power of LLMs would allow them to help with a range of statistical analyses. Also, their linguistic capabilities could translate ideas across human and programming languages. Those skills could be especially useful in large research networks, which consist of individuals from different countries and who have different programming skills. However, having LLMs author an original manuscript instead of a researcher would raise similar ethical concerns to allowing LLMs to function as an autonomous clinician. The education tasks raised the fewest ethical concerns, perhaps because students have regular supervision and a smaller role in direct patient care than clinicians or researchers.
Our sampling method followed a defined set of recruitment criteria and enrolled a total of 30 practicing clinicians who completed the survey for this study. While a larger number of respondents would have been desirable, ours covered a variety of clinical domains and provided valuable, original insights regarding the ethical and reliable uses of LLMs in clinical settings. Given the unusually rapid evolution of LLM technology, this early study is timely and makes meaningful contributions by including the voices of key stakeholders of implementing LLMs for clinical tasks.
A limitation of our study, and a potential source of sampling bias, is that only a relatively small number of participants from a single medical center were recruited by convenience sampling. Also, we used self-reported data as key elements of our analysis. These data may have introduced biases due to varying accuracy in self-reports and varying awareness of the problems by reporting individuals. Despite these limitations, we have developed an instrument that is capable of discerning different opinions about LLM use. We hope our findings can be taken into consideration by developers as the field continues its rapid evolution. As further progress is made, and clinicians have more significant experience with this technology, subsequent studies can build on our methods and experience to study larger sample sizes at multiple institutions to gain additional insights for future directions.
Future studies with a larger and more diverse sample will be warranted to ensure the generalizability of the results and allow for stratification by variables that could affect perceptions of LLM use, such as age, duration of clinical training, provider specialty, and experience with the technology. Those perceptions could be tracked longitudinally to gauge how they change over time. A more robust study about participants' general knowledge of LLMs and AI would strengthen future studies. Specifically, gauging to what extent participants understand how an AI algorithm is able to work, predict, learn, and generate responses, would be a valuable part of an analysis. Furthermore, comparing the perceptions regarding different LLMs, and how LLM-generated errors compare with human errors, may provide a more balanced view of the technology.
Our study found that health care providers would prefer to have LLMs assist than replace them. That finding has implications for future development and implementation of LLMs in clinical practice, research, and education. Studying active clinicians with novice LLM experience helped identify that preference. Therefore, for optimal development and implementation of LLMs in health care, continued human centered development is critical.
Conclusion
Clinicians are generally supportive of the use of LLMs for many tasks in clinical practice, research, and education, especially where LLMs play a supportive role to humans. Continued human centered development of the technology is critical.
Clinical Relevance Statement
Clinical Relevance Statement
We studied health care providers about the best uses of LLMs in health care. The clinicians who we studied were encouraging of having LLMs assist them for a range of tasks. The results of our work have implications for implementation of LLMs in health care.
Multiple Choice Questions
Multiple Choice Questions
-
Which of the following are ethical concerns about LLM use?
-
Efficiency
-
Confabulation or hallucination
-
Ability to synthesize information
-
Capacity to make technical language accessible
Answer: b. Confabulation or hallucination can cause the LLMs to generate false information, which can lead to incorrect medical decisions. The other answer choices are advantages of the technology.
-
What is the fundamental theorem of biomedical informatics?
-
An information resource is better without assistance from a person.
-
An information resource working in partnership with a person is better than an information resource unassisted.
-
A person working in partnership with an information resource is better than that same person unassisted.
-
A person is better without an information resource.
Answer: c. The fundamental theorem of biomedical informatics states that people are more effective when partnered with an information resource. The alternatives, which are to have no cooperation with information resources and people, or to have people assist information resources, are less effective.





